Module Top-100-Liked
双指针
二分查找
回溯算法
动态规划
哈希表
数组
栈和队列
链表
- add_two_numbers
- copy_list_with_random_pointer
- intersection_of_two_linked_lists
160.相交链表【遍历链表】
双指针解法,本质是构造两条等长链表。假设
a长度为lenA,b长度为lenB,共同长度为lenC,补齐各自缺少对方的节点,构造出两条同样长的新链表。 则lenA + lenC + lenB = lenB + lenC + lenA。 由于a和b两个走的路程是一样长的,把相交节点叫NodeC,则a,b两者走到的终点就是NodeC。其中NodeC可以是一个节点或者null空节点。// A: 1 -> 2 -> 3
// -> C -> 4 -> 5 -> null
// B: 6 -> 7
// A + B: 1 -> 2 -> 3 -> C(相交点) -> 4 -> 5 -> null -> 6 -> 7 -> C(相交点) -> 4 -> 5 -> null
// B + A: 6 -> 7 -> C(相交点) -> 4 -> 5 -> null -> 1 -> 2 -> 3 -> C(相交点) -> 4 -> 5 -> null- linked_list_cycle
- linked_list_cycle_ii
- lru_cache
- merge_k_sorted_lists
- merge_two_sorted_lists
- palindrome_linked_list
- remove_nth_node_from_end_of_list
- reverse_linked_list
- reverse_nodes_in_k_group
25.K个一组翻转链表【反转链表】
“反转链表的一部分”跟“反转整条链表”不少操作是类似的。反转同样需要运用到三个指针pre、cur、nxt。其中pre指向当前节点的前一个节点,cur指向当前节点,nxt指向当前节点的下一个节点。利用头插法完成反转。
相对于“反转整条链表”,“反转链表的一部分”需要应用到一些性质:
- 反转链表部分结束之后,pre就是反转部分链表的头部。而cur在pre后边,它代表着反转部分的右边头部。
- 我们把反转部分链表的尾部的前一个节点叫做p0,p0的next指向反转好的链表的尾部。 因此,反转完链表的部分后,我们还需要把p0的next节点的next指向cur,然后让p0的next指向pre,这样子才算完成了链表部分反转。
特殊情况,当left为1的时候,反转部分的前一个节点是无法找到p0的,为了统一逻辑,我们引入一个虚拟头节点dummy,让dummy的next指向head。这样子我们就可以认为当left为1的时候,p0就是dummy。
- sort_list
- swap_nodes_in_pairs
二叉树
- binary_tree_inorder_traversal
- binary_tree_level_order_traversal
- binary_tree_maximum_path_sum
- binary_tree_right_side_view
- construct_binary_tree_from_preorder_and_inorder_traversal
- convert_sorted_array_to_binary_search_tree
- diameter_of_binary_tree
- flatten_binary_tree_to_linked_list
- invert_binary_tree
- kth_smallest_element_in_a_bst
- lowest_common_ancestor_of_a_binary_tree
- maximum_depth_of_binary_tree
- path_sum_iii
- symmetric_tree
- validate_binary_search_tree
网格图
- course_schedule
三色标记法 + dfs
- implement_trie_prefix_tree
Trie树
- number_of_islands
四个方向dfs插旗
- rotate_image
48.旋转图像【matrix】
观察交换规律,看成上下左右,每个方向控制几个数。比如3*3的矩阵,上下左右分别控制2个数。t, b, l, r 指针围成一个圈,t控制上,b控制下,l控制左,r控制右。比如:
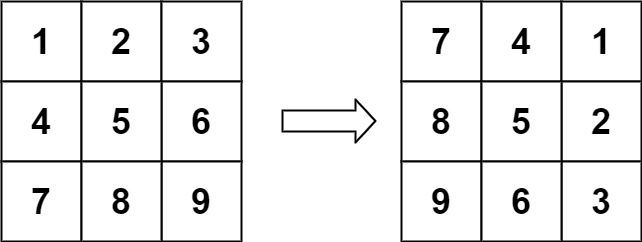 。
。可以看成是t控制了第一排前两个数(1, 2),r控制了最后一列的前两个数(3, 6)。b控制了最后一排从右数的两个数(9, 8),l控制第一列的从下数的前两个数(7, 4)。错开来看,规律就出来了:
-
第1轮-第1次
- 坐标在 (b + 0, l) 的元素来到坐标在 (t, l + 0) 的元素位置,
- 坐标在 (t, l) 的元素来到坐标在 (t, r) 的元素位置,
- 坐标在 (t + 0, r) 的元素来到坐标在 (b, r) 的元素位置。
-
第1轮-第2次
- 坐标在 (b + 1, l) 的元素来到坐标在 (t, l + 1) 的元素位置
- 坐标在 (t, l + 1) 的元素来到坐标在 (t + 1, r) 的位置
- 坐标在 (t + 1, r) 的元素来到坐标在 (b, r - 1) 的位置
次数的确定由 r - l 决定,或者 b - t 决定。而具体进行多少轮?只要 b > t && l < r 就继续,否则停止。
-
- rotting_oranges
- search_a_2_d_matrix_ii
- set_matrix_zeroes
- spiral_matrix
11.盛最多水的容器